Anytone AT-D878 : importer les contacts DMR sans les caractères spéciaux

Les dernières versions de la radio Anytone AT-D878UVII Plus peuvent contenir jusqu’à 500 000 contacts ce qui permet de télécharger et d’importer en une fois toute la base de contacts DMR (un peu plus de 200 000 contacts au moment de rédiger cet article).
Pourquoi importer tous les contacts et ne pas simplement enregistrer les quelques amis avec qui vous faite QSO ? Et bien ainsi, lorsque vous être sur un nouveau TG, vous pouvez quand même voir apparaitre l’indicatif radio et le nom de l’OM/YL qui parle. Plus pratique à retenir qu’un CSS7 composé de 7 chiffres absconds.
Différentes sources vous proposent de télécharger cette fameuse liste de contact :
Le problème
Les contacts sont extraits tels quels sans considération pour le jeu de caractères utilisé par la radio. Résultat, les accents et autres caractères spéciaux apparaissent « déformés » ou remplacés par des points d’interrogation.
Le problème vient clairement du CPS (customer programming software) d’Anytone et non du fichier d’import car en saisissant le nom, il apparait correctement jusqu’à la sauvegarde et la réouverture du fichier.


Première solution le charset (ça ne fonctionne pas)
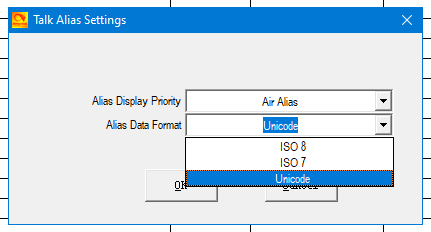 En cherchant un peu, j’ai remarqué que le CPS offrait le support de trois jeux de caractères
En cherchant un peu, j’ai remarqué que le CPS offrait le support de trois jeux de caractères
- ISO7
- ISO8
- Unicode
Il s’agit peu ou prou de la même chose, chaque fois, mais je me suis dit « qui sait, peut-être que l’un d’eux résoudra mon problème ».
Seconde solution supprimer les accents (oui mais…)
Plus facile à dire qu’à faire. On m’a naïvement suggéré de remplacer les quelques accents que l’on utilise le plus fréquemment en français, hélas la base de données et mondiale et le nombre de caractères spéciaux est assez impressionnant.
Ajouter à cela le temps pour effectuer un seul « rechercher/remplacer » dans un fichier Excel de 200 000 lignes ou dans le bloc-notes de Windows… et je ne vous parle même pas de Notepad++ qui plante purement et simplement.
J’ai tenté de recopier une macro, mais là aussi le temps est inimaginable (je soupçonne aussi Excel de planter pendant le traitement).
Ma méthode
Objectifs
- Limiter le temps de traitement
- Ne pas y passer plus de 15 minutes de mon temps
- Ne pas devoir laisser tourner la macro toute une nuit
- Vérifier qu’il n’y a pas de plantage en affichant un compteur indiquant la ligne en cours de traitement
- Automatiser au maximum : limiter la préparation du fichier en entrée pour pouvoir mettre à jour la liste en toute simplicité.
Organisation du travail
Dans un premier temps, je répertorie les caractères spéciaux présents. L’idée est de traiter un maximum des caractères courants et d’identifier les caractères plus rares afin de ne pas avoir à traiter le minimum de caractères spéciaux ce qui revient à limiter le temps de traitement (mon premier objectif).
Pour ce faire, je remplace une par une les 26 lettres de l’alphabet et les signes de ponctuations dans le Bloc-notes de Windows. Pourquoi le Bloc-notes de Windows parce que les logiciels plus avancés plantent ou prennent bien plus de temps a effectuer l’opération alors qu’une simple Expression Régulière [A-Z][a-z] aurait permit de sélectionner tous les caractères à supprimer en une fois ☹
Sub SupprimerCaracterNormaux(zone) Rem On ne supprime surtout pas le caractère 42 = *. Rem On supprime la ponctuation (code ASCII 33 à 41). For i = 33 To 41 Range(zone).Replace What:=Chr(i), Replacement:="" Next i Rem On supprime les symboles mathématiques et les chiffres (code 43 à 62). For i = 43 To 62 Range(zone).Replace What:=Chr(i), Replacement:="", MatchCase:=False Next iRem On ne supprime surtout pas le caractères 63 = ?. Rem On supprime les lettres (64 à 90) et encore quelques symboles. For i = 64 To 96 Range(zone).Replace What:=Chr(i), Replacement:="" Next i Rem On supprime encore les accolades. For i = 123 To 125 Range(zone).Replace What:=Chr(i), Replacement:="" Next i Rem On supprime les espace et les virgules. Range(zone).Replace What:=" ", Replacement:="" Range(zone).Replace What:=",", Replacement:="" End Sub
Ensuite, je vérifie les colonnes vides. Supprimer les colonnes vides permet d’accélérer les traitements ultérieurs.
Sub Concatener() Rem On nettoie les caractères ASCII pour rendre possibles les traitements ultérieurs. SupprimerCaracterNormaux ("A:J")Rem On fixe le nombre de ligne que lequel travailler nb_lignes = 240000Rem Insertion d'une colonne qui recevra tous les caractères de chaque ligne. tous_caractere = WorksheetFunction.Concat(Range("A1:J" & nb_lignes))Rem Création d'une colonne ou figurera chaque caractère trouvé, un à un dans une case. Columns(1).InsertFor i = 1 To Len(tous_caractere) Cells(i, 1) = Mid$(tous_caractere, i, 1) Range("L1") = i Next i Rem Suppression des doublons : on tri d'abord la colonne. With ActiveSheet.Sort .SortFields.Add Key:=Columns("A:A") .SetRange Columns("A:A") .Apply End WithRem Suppression des doublons. ActiveSheet.Range("A:A").RemoveDuplicates Columns:=1Rem Suppression des caractères ASCII restants à l'aide de la fonction ci-dessus. SupprimerCaracterNormaux ("A:A") End Sub
Une fois chaque caractère identifié j’ai créé un tableau de correspondance pour savoir par quelle lettre le substituer, hélas, nous obtenons une liste de 800 caractères, je ne m’attendais pas à autant.
Si on y regarde de plus près, nous avons :
- Des signes de ponctuations exotiques

- Des symboles ressemblant à des caractères latins mais qui n’en sont pas si on regarde leur code ASCII

- Des caractères latins accentués

- Des caractères grecs (on trouveras la translitération sur Wikipédia notamment)

- Des caractères cyrilliques (la translitération se trouve aussi sur Wikipédia)

- Des caractères asiatiques
- Japonais

- Thaï

- Coréen
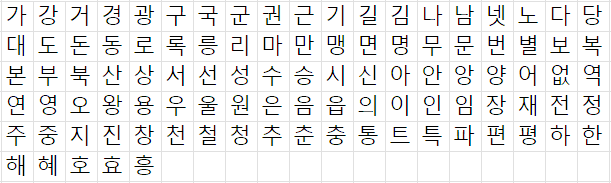
- Chinois (400 symboles, soit la moitié de la liste)

- Japonais
Devant la charge de travail représentée par la translitération des caractères asiatiques, j’ai décidé de ne travailler que sur les caractères latins. J’ai créé un tableau de correspondance pour savoir par quelle lettre le substituer puis une formule Excel pour créer les ligne de substitution en VBA.
=".Add"""&A1&""", """&B1&""""
Où A1 est le caractère à remplacer et B1 le caractère de remplacement.
Et là, c’est le drame ! Une fois toutes les chaines de substitution copiées dans l’éditeur VBA, je m’aperçois que seuls certains caractères accentués subsistent, les langues asiatiques font défauts ainsi que quelques caractères spéciaux exotiques.

Il me faut donc supprimer tous ces caractères, premièrement parce que le dictionnaire de substitution ne peut contenir qu’une seule fois chaque caractère à remplacer et deuxièmement le point d’interrogation est considéré comme un joker qui signifie « n’importe quel symbole » et donc tous les caractères du fichier seraient remplacés ce qui serait un peu gênant.
Au final, il ne reste plus que 65 caractères remplaçables, ce qui devrait considérablement accélérer le traitement.

Le code VBA s’exécute en quelques dizaines de secondes et ressemble à cela :
Sub remplacer()
Set replacements = CreateObject("Scripting.dictionary")
With replacements
.Add "–", "-"
.Add "~", ""
.Add "¡", "i"
.Add "¦", "|"
.Add "¨", ""
.Add "´", "'"
.Add "¸", ""
.Add "¿", ""
.Add "’", "'"
.Add "‚", ","
.Add "“", '"'
.Add "”", '"'
.Add "‹", "<" .Add "›", ">"
.Add "¤", ""
.Add "¥", "Y"
.Add "±", ""
.Add "©", "(c)"
.Add "°", "o"
.Add "¶", ""
.Add "•", "."
.Add "ƒ", "f"
.Add "„", '"'
.Add "…", "..."
.Add "‡", ""
.Add "Ÿ", "Y"
.Add "¼", "1/4"
.Add "½", "1/2"
.Add "¾", "3/4"
.Add "²", "2"
.Add "³", "3"
.Add "ª", "a"
.Add "Á", "A"
.Add "à", "a"
.Add "â", "a"
.Add "ä", "a"
.Add "Ã", "A"
.Add "å", "a"
.Add "Æ", "AE"
.Add "ç", "c"
.Add "é", "e"
.Add "è", "e"
.Add "ê", "e"
.Add "ë", "e"
.Add "í", "i"
.Add "ì", "i"
.Add "Î", "i"
.Add "ï", "i"
.Add "ñ", "n"
.Add "º", "o"
.Add "ó", "o"
.Add "ò", "o"
.Add "ô", "o"
.Add "ö", "o"
.Add "Õ", "o"
.Add "Ø", "e"
.Add "œ", "oe"
.Add "š", "s"
.Add "ß", "ss"
.Add "ú", "u"
.Add "ù", "u"
.Add "ü", "u"
.Add "ý", "y"
.Add "ž", "z"
End With
For Each Key In replacements.Keys
Value = replacements(Key)
If Key <> Value Then
Range("A:J").Replace What:=Key, Replacement:=Value, LookAt:=xlPart
End If
Next
End Sub
Et voilà !
Si vous avez des remarques, des suggestions, des questions, n’hésitez pas ➡️ utilisez les commentaires ⬇️
Laisser un commentaire